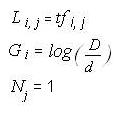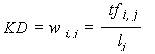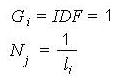The Keyword Density of Non-Sense.
by DR. E. Garcia - March 2005
On March 24 a FINDALL search in Google for keywords
density optimization returned 240,000 documents. I found
many of these documents belonging to search engine marketing
and optimization (SEM, SEO) specialists. Some of them promote
keyword density (KD) analysis tools while others talk about
things like “right density weighting”, “excellent keyword
density”, KD as a “concentration” or “strength” ratio and
the like. Others even take KD for the weight of term i in
document j, while others propose localized KD ranges for titles,
descriptions, paragraphs, tables, links, urls, etc. One can
even find some specialists going after the latest KD “trick”
and claiming that optimizing KD values up to a certain range
for a given search engine affects the way a search engine
scores relevancy and ranks documents.
Given the fact that there are so many KD theories flying
around, my good friend Mike Grehan approached me after the
Jupitermedia’s 2005 Search Engine Strategies Conference held
in New York and invited me to do something about it. I felt
the "something" should be a balanced article mixed with a
bit of IR, semantics and math elements but with no conclusion
so readers could draw their own. So, here we go.
Background.
In the search engine marketing literature, keyword density
is defined as
| Equation 1 |
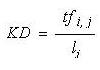 |
where tfi, j is the number of times term i appears in document
j and l is the total number of terms in the document. Equation
1 is a legacy idea found intermingled in the old literature
on readability theory, where word frequency ratios are calculated
for passages and text windows - phrases, sentences, paragraphs
or entire documents - and combined with other readability
tests.
The notion of keyword density values predates all commercial
search engines and the Internet and can hardly be considered
an IR concept. What is worse, KD plays no role on how commercial
search engines process text, index documents or assign weights
to terms. Why then many optimizers still believe in KD values?
The answer is simple: misinformation.
If two documents, D1 and D2, consist of 1000 terms (l = 1000)
and repeat a term 20 times (tf = 20), then for both documents
KD = 20/1000 = 0.020 (or 2%) for that term. Identical values
are obtained if tf = 10 and l = 500.
Evidently, this overall ratio tells us nothing about:
1. the relative distance between keywords in documents (proximity)
2. where in a document the terms occur (distribution)
3. the co-citation frequency between terms (co-occurrence)
4. the main theme, topic, and sub-topics (on-topic issues)
of the documents
Thus, KD is divorced from content quality, semantics and
relevancy. Under these circumstances one can hardly talk about
optimizing term weights for ranking purposes. Add to this
copy style issues and you get a good idea of why this article's
title is The Keyword Density of Non-Sense.
The following five search engine implementations illustrate
the point:
1. Linearization
2. Tokenization
3. Filtration
4. Stemming
5. Weighting
Linearization.
Linearization is the process of ignoring markup tags from
a web document so its content is reinterpreted as a string
of characters to be scored. This process is carried out tag-by-tag
and as tags are declared and found in the source code. As
illustrated in Figure 1, linearization affects the way search
engines “see”, “read” and “judge” Web content --sort of speak.
Here the content of a website is rendered using two nested
html tables, each consisting of one large cell at the top
and the common 3-column cell format. We assume that no other
text and html tags are present in the source code. The numbers
at the top-right corner of the cells indicate in which order
a search engine finds and interprets the content of the cells.
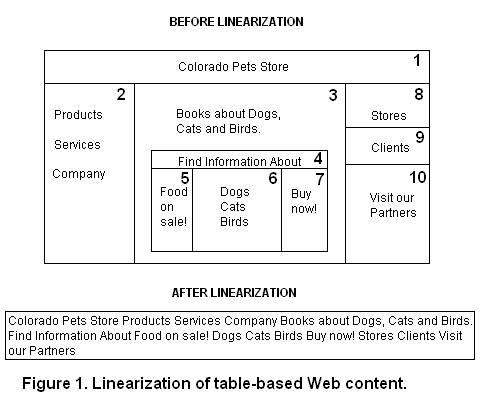
The box at the bottom of Figure 1 illustrates how a search
engine probably “sees”, “reads” and “interprets” the content
of this document after linearization. Note the lack of coherence
and theming. Two term sequences illustrate the point: "Find
Information About Food on sale!" and "Clients Visit our Partners".
This state of the content is probably hidden from the untrained
eyes of average users. Clearly, linearization has a detrimental
effect on keyword positioning, proximity, distribution and
on the effective content to be “judged” and scored. The effect
worsens as more nested tables and html tags are used, to the
point that after linearization content perceived as meritorious
by a human can be interpreted as plain garbage by a search
engine. Thus, computing localized KD values is a futile exercise.
Burning the Trees and Keyword Weight Fights.
In the best-case scenario, linearization shows whether words,
phrases and passages end competing for relevancy in a distorted
lexicographical tree. I call this phenomenon “burning the
trees”. It is one of the most overlooked web design and
optimization problems.
Constructing a lexicographical tree out of linearized content
reveals the actual state and relationship between nouns, adjectives,
verbs, and phrases as they are actually embedded in documents.
It shows the effective data structure that is been used. In
many cases, linearization identifies local document concepts
(noun groups) and hidden grammatical patterns. Mandelbrot
has used the patterned nature of languages observed in lexicographical
trees to propose a measure he calls the "temperature of discourse".
He writes: "The `hotter’ the discourse, the higher the probability
of use of rare words.” (1). However, from the semantics standpoint,
word rarity is a context dependent state. Thus, in my view
"burning the trees" is a natural consequence of misplacing
terms.
In Fractals and Sentence Production, Chapter 9 of From Complexity
to Creativity (2, 3), Ben Goertzel uses an L-System model
to explain that the beginning of early childhood grammar is
the two-word sentence in which the iterative pattern involving
nouns (N) and verbs( V) is driven by a rule in which V is
replaced by V N (V >> V N). This can be illustrated with the
following two iteration stages:
0 N V (as in Stevie byebye)
1 N V N (as in Stevie byebye car)
Goertzel explains, "-The reason N V is a more natural combination
is because it occurs at an earlier step in the derivation
process." (3). It is now comprehensible why many Web documents
do not deliver any appealing message to search engines. After
linearization, it can be realized that these may be "speaking"
like babies. [By the way, L-System algorithms, named after
A. Lindermayer, have been used for many years in the study
of tree-like patterns (4)].
"Burning the trees" explains why repeating terms in a document,
moving around on-page factors or invoking link strategies,
not necessarily improves relevancy. In many instances one
can get the opposite result. I recommend SEOs to start incorporating
lexicographical/word pattern techniques, linearization strategies
and local context analysis (LCA) into their optimization mix.
(5)
In Figure 1, “burning the trees” was the result of improper
positioning of text. However in many cases the effect is a
byproduct of sloppy Web design, poor usability or of improper
use of the HTML DOM structure (another kind of tree). This
underscores an important W3C recommendation: that html tables
should be use for presenting tabular data, not for designing
Web documents. In most cases, professional web designers can
do better by replacing tables with cascading style sheets
(CSS).
“Burning the trees” often leads to another phenomenon I call
“keyword weight fights”. It is a recurrent problem
encountered during topic identification (topic spotting),
text segmentation (based on topic changes) and on-topic analysis
(6). Considering that co-occurrence patterns of words and
word classes provide important information about how a language
is used, misplaced keywords and text without clear topic transitions
difficult the work of text summarization editors (humans or
machine-based) that need to generate representative headings
and outlines from documents.
Thus, the "fight" unnecessarily difficults topic disambiguation
and the work of human abstractors that during document classification
need to answer questions like “What is this document or passage
about?”, “What is the theme or category of this document,
section or paragraph?”, “How does this block of links relate
to the content?”, etc.
While linearization renders localized KD values useless,
document indexing makes a myth out of this metric. Let see
why.
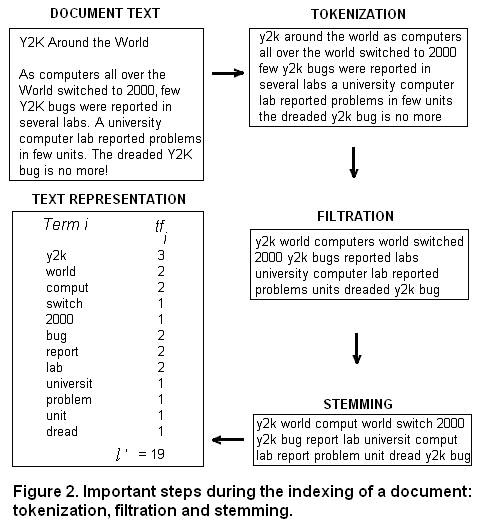
Tokenization, Filtration and Stemming
Document indexing is the process of transforming document
text into a representation of text and consists of
three steps: tokenization, filtration and stemming.
During tokenization terms are lowercased and punctuation
removed. Rules must be in place so digits, hyphens and other
symbols can be parsed properly. Tokenization is followed by
filtration. During filtration commonly used terms and
terms that do not add any semantic meaning (stopwords) are
removed. In most IR systems survival terms are further reduced
to common stems or roots. This is known as stemming.
Thus, the initial content of length l is reduced to a list
of terms (stems and words) of length l' (i.e., l' < l). These
processes are described in Figure 2. Evidently, if linearization
shows that you have already "burned the trees", a search engine
will be indexing just that.
Similar lists can be extracted from individual documents
and merged to conform an index of terms. This index can be
used for different purposes; for instance, to compute term
weights and to represent documents and queries as term vectors
in a term space.
Weighting.
The weight of a term in a document consists of three different
types of term weighting: local, global, and normalization.
The term weight is given by
where Li, j is the local weight for term i in document j,
Gi is the global weight for term i and Nj is the normalization
factor for document j. Local weights are functions of how
many times each term occurs in a document, global weights
are functions of how many times documents containing each
term appears in the collection, and the normalization factor
corrects for discrepancies in the lengths of the documents.
In the classic Term Vector Space model
which reduces to the well-known tf*IDF weighting scheme
where log(D/di) is the Inverse Document Frequency (IDF),
D is the number of documents in the collection (the database
size) and di is the number of documents containing term i.
Equation 6 is just one of many term weighting schemes found
in the term vector literature. Depending on how L, G and N
are defined, different weighting schemes can be proposed for
documents and queries.
KD values as estimators of term weights?
The only way that KD values could be taken for term weights
is if global weights are ignored and the normalization factor
Nj is redefined in terms of document lengths
However, Gi = IDF = 1 constraints the collection size D to
be equal to ten times the number of documents containing the
term (D = 10*d) and Nj = 1/lj implies no stopword filtration.
These conditions are not observed in commercial search systems.
Using a probabilistic term vector scheme in which IDF is
defined as
does not help either since the condition Gi = IDF = 1 implies
that D = 11*d. Additional unrrealistic constraints can be
derived for other weighting schemes when Gi = 1.
To sum up, the assumption that KD values could be taken for
estimates of term weights or that these values could be used
for optimization purposes amounts to the Keyword Density
of Non-Sense.
References
The Fractal Geometry of Nature, Benoit B. Mandelbrot, Chapter
38, W. H. Freeman, 1983.
From
Complexity to Creativity: Computational Models of Evolutionary,
Autopoietic and Cognitive Dynamics, Ben Goertzel, Plenum
Press (1997).
Fractals
and Sentence Production, Ben Goertzel, Ref 2, Chapter
9, Plenum Press (1997).
The Algorithmic Beauty of Plants, P. Prusinkiewicz and A.
Lindenmayer, Springer-Verlag, New York, 1990.
Topic
Analysis Using a Finite Mixture Model, Hang Li and Kenji
Yamanish.
Improving
the Effectiveness of Information Retrieval with Local Context
Analysis, Jinxi Xu, W. Bruce Croft.
© Dr. E. Garcia. 2005
Editor: Mike Grehan. Search
engine marketing consultant, speaker and author.
http://www.search-engine-book.co.uk
Associate Editor: Christine
Churchill. KeyRelevance.com
e-marketing-news is published
selectively on a when it's
ready basis. ©2005 Net Writer Publishing.
At no cost you may use the
content of this newsletter on
your own site, providing you display it in its entirety
(no cutting) with due credits and place a link to:
< http://www.e-marketing-news.co.uk
>

|